What is federated learning?
Federated learning (FL) is a machine learning paradigm that allows to train algorithms collaboratively without the need for source data exchange between the parties. This means that different institutions or companies can join forces in the development of data-driven solutions without sharing their secrets. Participants in such a venture come together in an FL consortium. How this may work is outlined below. There is also a quick peek at a speculative topical use case at the end.
Federated learning healthcare consortia
The pre-print paper by Passerat-Palmbach J et al. (2019) [basically the folk from ConsenSys Health] suggests an FL architecture intended to be suitable for the healthcare sector. Here, I am trying to digest the idea by cutting out most of the jargon and technological detail to simply get a feel for its process flow.
The set-up
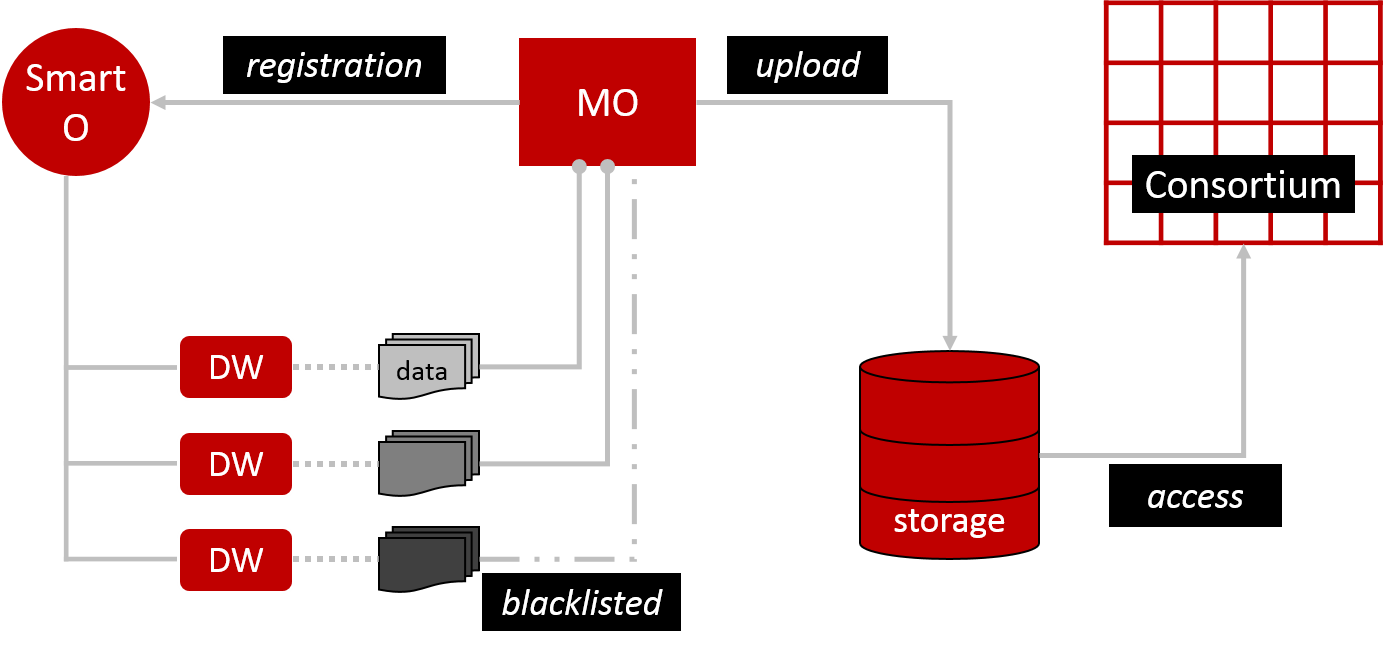
To launch the FL process we need a computational model, which is uploaded into distributed storage by the Model Owner (MO) (Figure 1). This basically means storing the model on multiple servers that behave as one system (like a flock of birds). All members of the consortium have access to this storage. The MO also registers its model and training description via an Orchestrator smart contract (Smart O). This is essentially a computer protocol to automate the model’s processes. Smart O also maintains a list of Data Workers (DW). DW hold datasets that will train MO’s model. However, DW can prevent access to some or all of their data by blacklisting specified MO. I’m not sure why blacklisting was chosen over whitelisting. From a practical user perspective, blacklisting may be more convenient for small consortia where the default intention is to be connected, which arguably could be a healthcare scenario. In large consortia, I assume, whitelisting makes it easier to keep track of who has access. It would be like adding ‘friends’ to your social media profile rather than having the whole world as your default friends and then having to remove them all bar your wanted connections.
A training round
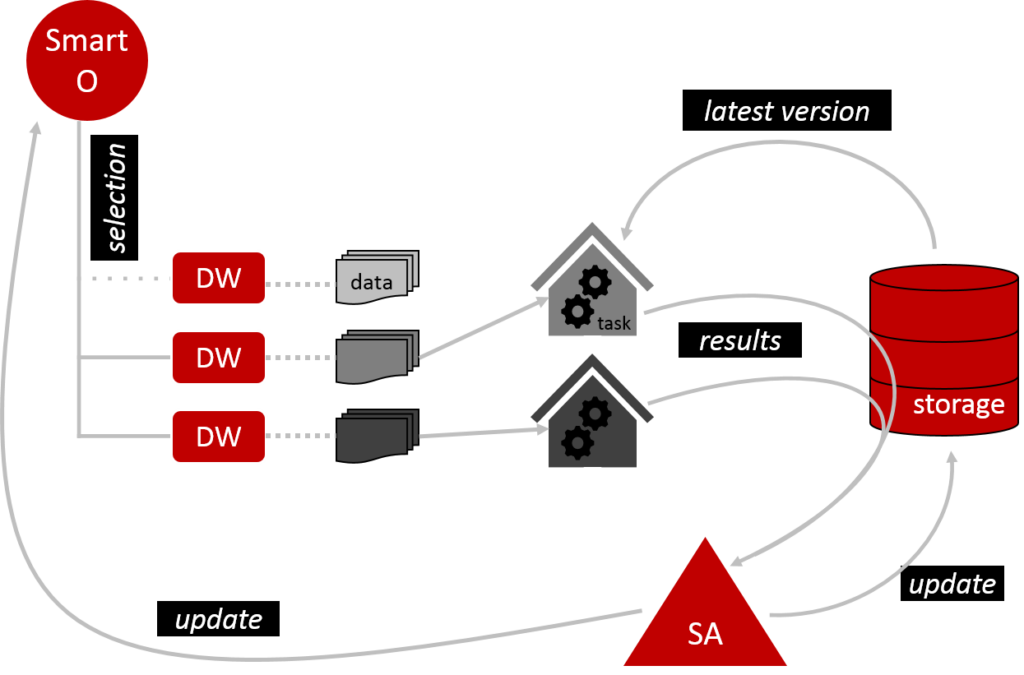
Once the set-up is complete, we can start training MO’s model (Figure 2). Smart O checks which DW are eligible to participate and excludes those which are not. It then arranges for the eligible DW to perform the training tasks as prescribed by MO. DW work in a private environment, so they don’t need to share their data with anyone. Before DW get started, they download the latest version of the model from the shared storage. Once they have run their data through the model, they submit their results via the storage to the Secure Aggregator (SA). SA collates these results to modify the model and load the updated version back into the storage. SA also updates Smart O. One training round is now complete. In principle, this can be repeated over and over to mature the model.
Whispers
When DW submit their results, they encrypt them first. SA then decrypts them safely in order to complete the pooling and integration of results. It is a bit as if DW whispered to SA and nobody else can hear. However, SA has selective hearing. It randomly excludes results to protect DW. The idea is that malicious DW could collude and share their results. Based on this knowledge, they could then deduce the remaining DW’s results from the modified model; just as we can figure out that x = 3 in the equation 1 + 2 + x = 6. Thanks to random selection nobody knows whose results have been used in each training round. Thus, even collusion is futile.
Leaving a trail
The magic described above happens on an Ethereum-based blockchain. Consequently, an immutable audit trail is created by logging all applicable actions. Leaving a trail is worrisome when privacy is paramount. However, SA takes care of this concern by generating an anonymous unique one-off ID for each DW per training round. The unique temporary ID is published on the blockchain. Only the single DW and SA are able to derive the DW’s identity directly from the published ID as long as they keep the key to unlock the secret safely tucked away. Even if someone manages to de-anonymise a DW’s identity in one round through some other factors, it will be different in the next round.
On another note, using Ethereum also means that a payment mechanism could be implemented to allocate tokens to DW as a reward for their participation.
Data are the life blood
Leaving all other complexities aside, let’s briefly consider a fundamental aspect of FL: the quality of the underlying datasets. Any data-driven application lives or dies by its source data. “Rubbish in. Rubbish out.”, as they say. Some obvious questions we could ask: How have data been collected and treated? In which format are data presented? How are data from different sources structured? Is it possible to extract what’s needed? Is there a bias in the population, which would skew the model? I believe that alongside the development of fancy tech, stakeholders should not lose sight of promoting IT literacy, cultures of proper data management and standards that keep up with technological evolution.
Isn’t this just a playground for geeks?
Nope. Not anymore.
We are seeing a drive to collaborate in the healthcare sector. This has been made even more pressing by the current COVID-19 pandemic. Companies are not only falling over themselves churning out new coronavirus diagnostic kits, they are also researching potential vaccines and treatments. (I started tracking this a wee bit from February onwards in my monthly biotech review.) Some of this effort has spawned unheard of degrees of collaboration and data sharing.
Take, for example, the collaboration of 15 pharma companies (including Novartis, Pfizer, Johnson & Johnson, Merck and Sanofi) with the Bill & Melinda Gates Foundation. This involves sharing parts of proprietary compound libraries! I’m not clear on who’s getting access to what. It sounds like the research will be channelled through the Foundation’s COVID-19 Therapeutics Accelerator. This could mean that the collaboration hinges on a trusted neutral party, the Gates Foundation, that knows all the data owners (hello Orchestrator) and collates the data and results (hello Aggregator).
Imagine we already had the type of FL environment described above. Participants would join because they know that privacy is protected by design without the need to fully trust each other or a presumably neutral party. In the COVID-19 collaboration above this could mean that larger compound libraries are tested because the companies may feel less of a need to be selective (protective). As a result, compounds that are currently excluded might be assessed as well. In a quest to find a therapy for a disease with no known cure, compound selection could literally mean making a decision between life and death.
Now imagine a more complex consortium. There could be more pharma manufacturers, of course, but also academics, raw material suppliers or other entities along the supply chain. Models would not only iterate which active compound is the best bet in treating the disease, we could also find out what to do with it once that decision is made. How should the drug be formulated, i.e. which other components should be added? What’s the most suitable carrier substance? How should the therapy be applied, e.g. pill or injection? Should release of the active ingredient be fast or slow? I have no idea how such decisions are currently made. However, if there were drug development algorithms, using FL in a consortium that spans the supply chain, may introduce efficiencies and possibly surprising results.
Whilst the last few deliberations are speculative, note that there are already pharma/biotech consortia in the starting blocks, for example MELLODDY.
I hope I got the basics right. I haven’t written much about blockchain yet because I’m still trying to get my head around things (previous attempt here). If you have noticed any errors or suggestions for further reading, give me a shout on social media.
References
- Gross MS & Miller RC, 13/02/2020. https://www.statnews.com/2020/02/13/federated-learning-safer-collaboration-health-research/ (accessed 03/04/20)
- Passerat-Palmbach J et al., 2019. A blockchain-orchestrated Federated Learning architecture for healthcare consortia. arXiv:1910.12603v1 [cs.CY]
- Rieke N et al., 2020. The Future of Digital Health with Federated Learning. arXiv:2003.08119v1 [cs.CY]
- Taylor NP, 27/03/2020. Big Pharma companies join forces for fightback against COVID-19. https://www.fiercebiotech.com/biotech/big-pharma-companies-join-forces-for-fightback-against-covid-19 (accessed 01/04/20)
1 thought on “Federated learning in healthcare”
Comments are closed.